AWS Lambda is a serverless compute service which has been designed to allow you to run your application code without having to manage and provision your own EC2 instances. This saves you having to maintain and administer an additional layer of technical responsibility within your solution. Instead, that responsibility is passed over AWS to manage for you. If you don't need to spend time operating, managing, patching, and securing an EC2 instance, then you have more time to focus on the code of your application and its business logic, while at the same time optimizing costs.
You can either upload this code to AWS Lambda or write it within the code editors that Lambda provides.
¶ AWS Lambda supports:
-
Node.js, Python, Java, C#, Go, Ruby.
-
The code that you write or upload can also include other libraries.
-
Once your code is within Lambda, you then need to configure Lambda functions to execute your code upon specific triggers from supported event sources such as S3.
-
Example: a Lambda function could be triggered when an S3 event occurs, such as an object being uploaded to an S3 bucket. Once the specific trigger is initiated during your normal operations of AWS, AWS Lambda will run your code, as per your Lambda function, using only the required compute power as defined.
¶ Execution:
| Feature | Limit |
|---|---|
| Memory allocation | 128 MB - 10GB (1 MB increments) |
| Maximum execution time | 900 seconds (15 minutes) |
| Environment variables | 4 KB |
| Disk capacity in the "function container" (in /tmp) | 512 MB to 10GB |
| Concurrency executions | 1000 (can be increased) |
| API Gateway Timeout | 29 seconds |
| Synchronously-invoked function Payload | 6MB |
¶ Deployment:
| Feature | Limit |
|---|---|
| Lambda function deployment size (compressed zip) | 50 MM |
| Size of uncompressed deployment (code + dependencies) | 250 MB |
| Temp Directory available | /tmp |
| Size of environment variables | 4 KB |
¶ Pricing:
- Pay per request and compute time
- Free tier = 1,000,000 AWS Lambda requests
- 400,000 GBs of compute time
- $0.20/1mm requests (.0000002 per request after free tier)
- Easy monitoring through AWS CloudWatch
- Easy to get more resources per functions (up to 10GB of RAM!)
- Increasing RAM will also improve CPU and network!
- Pay per duration: (in increment of 1 Ms)
- 400,000 GB-seconds of compute time per month if FREE
- == 400,000 seconds if function is I GB RAM
- == 3,200,000 seconds if function is 128 MB RAM
- After that $ 1.00 for 600,000 GB-seconds
¶ Networking
- Lambda functions are launched outside your VPC (in an AWS owned VPC)
- You must provide Lambda with the VPC ID, Subnets and Security groups. It will then create an ENI in your subnets, allowing it the access it requires.
¶ RDS Proxy
- In order to limit the number of connections being made from lambda into your database, use a RDS proxy. Lambda funtions will all go through the Proxy and the proxy will only use a couple of DB connedtions, vs each lambda function getting it's own connection.
- This can also reduce failover time up to 66%, since the proxy will handle updating the connection to the new database.
- Allows IAM authentication and storing credentials in Secrets Manager.
- These lambda functions must be deployed w/in your VPC (Private), b/c rds proxy is not publically available.
¶ Lambda for RDS (PostgreSQL and MySQL)
- Databases can be configured to invoke Lambda functions based on database events.
- Must allow outbound traffic to your Lambda function from within your DB instance (Public, NAT GW, VPC Endpoints)
- DB instance must have the required permissions to invoke the Lambda function (Lambda Resource-based Policy & IAM Policy)
¶ RDS Event Notifications
- Have nothing to do with data. This is only for database events (startup, shutdown, created)
- Near realtime events (up to 5 minutes to get notification)
- Send notifications to SNS or subscribe to events using EventBridge.
l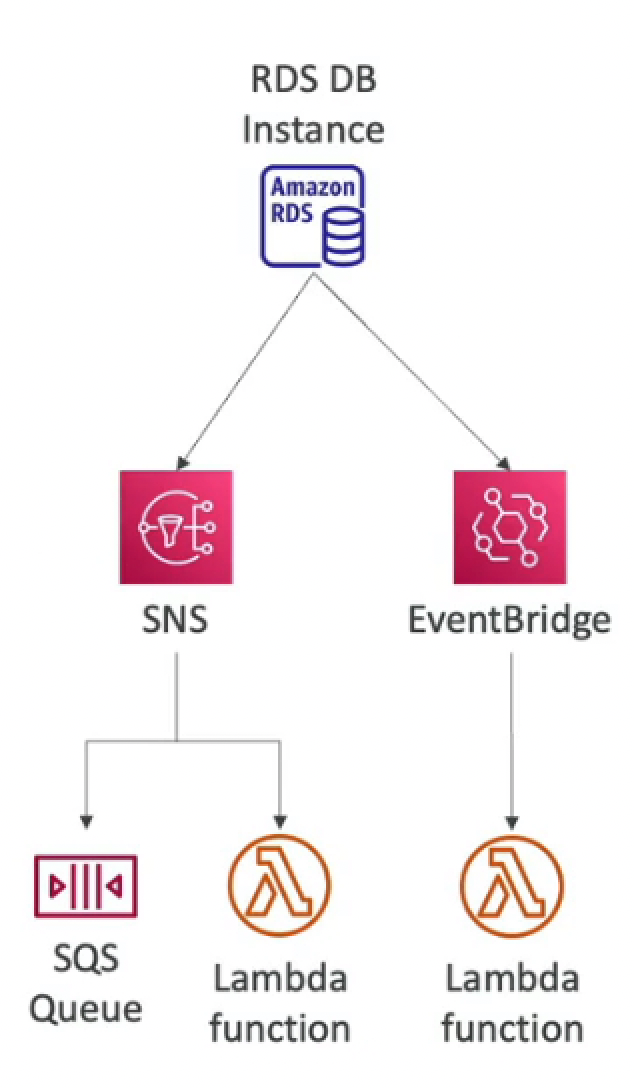
¶ Log streams
In an effort to help you identify issues and troubleshoot issues with your Lambda function, you can add logging statements to help you identify if your code is operating as expected into a log stream. These log streams will essentially be a sequence of events that all come from the same function and are recorded in CloudWatch. In addition to log streams, Lambda also sends common metrics of your functions to CloudWatch for monitoring and alerting.
¶ Configuration
¶ Deployment Package
- You must uload your code in either a .zip or .jar file with all the dependencies.
- Creation of the package depends on the programming language
- Need to set permissions with global read permissions.
- https://docs.aws.amazon.com/lambda/latest/dg/deployment-package-v2.html#lamgda-zip-package-permission-policies
zipinfo <test.zip>to test read permissions
- Use the following command to set permissions properly.
chmod 644 $(find /tmp/package_contents -type f)chmod 755$(find /tmp/package_contents -type d)- should see
-r--r--r--on all files.
- Windows, use 7zip, not Zipinfo
- Can upload code through management console, SDK or AWS CLI
¶ Info
You can import code into Lambda by creating a deployment package, and Lambda will need global read permissions to your deployment package to perform the import function. You can upload your code using the Management Console, AWS CLI or the SDK, and if you created your code from within Lambda itself, then Lambda would create the deployment package for you. There are three different options when creating a function. You can author it from scratch, use a blueprint, or use the serverless application repository.
You must provide the name of your function, the run time, and the IAM role to be used to create your function. The designer window in the function allows you to configure triggers, and a trigger is an operation from an event source that causes the function to invoke. Configured triggers are then added to the design window. To view policy information for the execution policy, and the function policy, you can select the key icon in the design window, and the role execution policy determines what resources the function role has access to when the function is being run. The function policy defines which AWS resources are allowed to invoke your function, and the function code window allows you to define, write, and import your code. The handler within your function allows Lambda to invoke it when the service executes the function on your behalf, and it's used as the entry point within your code to execute your function.
-
Environment variables: Key Value pairs that allow you to incorporate variables into your function without embedding them thoroughly into your code.
-
By default, AWS Lambda encrypts your environment variables after the function has been deployed using KMS.
-
Basic settings allows you to determine the compute resource that you want to use to execute your code, and you can only alter the amount of memory used. AWS Lambda then calculates the CPU power itself, based off of this selection. The function timeout determines how long the function should run before it terminates. And by default, AWS Lambda is only allowed to access resources that are accessible over the internet. To access resources within your VPC requires additional configuration.
-
The execution role will need permissions to configure ENIs in your VPC.
-
A dead-letter queue is used to receive payloads that were not processed due to a failed execution. Any failed asynchronous functions would automatically retry the event a further two more times. Synchronous invocations do not automatically retry failed attempts.
-
Enable active tracing is used to integrate AWS X-Ray to trace event sources that invoked your Lambda function, in addition to tracing other resources that were called upon in response to your Lambda function running.
-
Concurrency measures how many functions can be running at the same time, with a default unreserved concurrency set to 1,000. AWS CloudTrail integrates with AWS Lambda, aiding with auditing and compliance.
-
Throttling sets the reserved concurrency limit of your function to zero, and will stop all future invocations of the function until you change the concurrency setting.
-
Lambda qualifiers: allow you to change between versions of an alias of your function, and when you create a new version of your function, you're not able to make any further configuration changes, making it immutable.
-
An alias allows you to create a pointer to a specific version of your function.
-
By exporting your function, you can redeploy at a later stage, perhaps within a different AWS region. And by creating a test event, you can easily perform different tests against your function.
¶ Event sources
¶ poll-based
- Amazon Kinesis, Amazon SQS, and DynamoDB
- mappings are held within your Lambda function
- by manually invoking that Lambda function you have the ability to use the invoke option, allowing you to invoke it synchronously or asynchronously.
¶ push-based
-
all the remaining supported event sources.
-
the mapping is maintained within the event source
-
always have an invocation type of synchronous
-
Event Source Mapping: The configuration that links your event source to your Lambda function.
-
Synchronous invocation enables you to assess the result of the function before moving on to the next operation required, and asynchronous invocations can be used when there is no need to maintain an order of function execution.
¶ CloudWatch
- uses the following metrics: invocations, errors, dead letter errors, duration, throttles, iterator age, concurrent executions, and unreserved concurrent executions.
- In addition to these metrics, CloudWatch also gathers log data sent by Lambda.
- Each function relates to a different log group.
- The log group name is defined as AWS Lambda, and then the function name, and it's possible to create custom logging statements into your function code, which are then sent to CloudWatch logs.
- Common issues as to why your function might not run relate to permissions.
- Always check your IAM role execution policy and function policies to ensure the correct access has been issued to run your function.